The task is predicting the click through rate (CTR) of advertisement, meaning that we are to predict the probability of each ad being clicked. https://www.kaggle.com/c/kddcup2012-track2
Dataset
| File | Size | Records |
|---|---|---|
| KDD_Track2_solution.csv | 244MB | 20,297,595 (20,297,594 w/o header) |
| descriptionid_tokensid.txt | 268MB | 3,171,830 |
| purchasedkeywordid_tokensid.txt | 26MB | 1,249,785 |
| queryid_tokensid.txt | 704MB | 26,243,606 |
| test.txt | 1.3GB | 20,297,594 |
| titleid_tokensid.txt | 171MB | 4,051,441 |
| training.txt | 9.9GB | 149,639,105 |
| serid_profile.txt | 283MB | 23,669,283 |
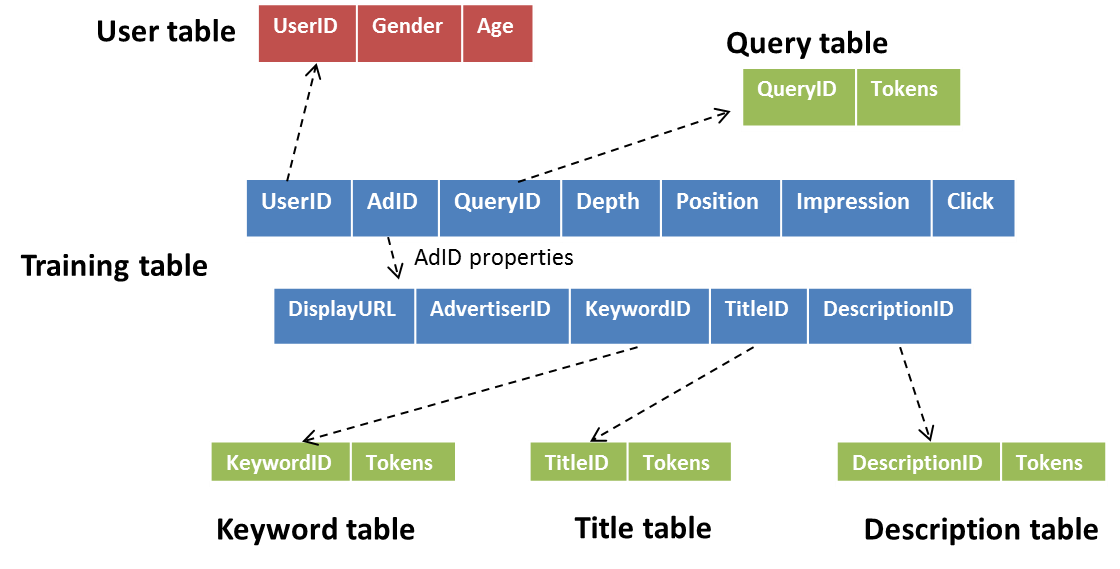
Tokens are actually not used in this example. Try using them on your own.
create database kdd12track2;
use kdd12track2;
Create external table training (
RowID BIGINT,
Clicks INT,
Impression INT,
DisplayURL STRING,
AdID INT,
AdvertiserID INT,
Depth SMALLINT,
Position SMALLINT,
QueryID INT,
KeywordID INT,
TitleID INT,
DescriptionID INT,
UserID INT
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE LOCATION '/kddcup2012/track2/training';
Create external table testing (
RowID BIGINT,
DisplayURL STRING,
AdID INT,
AdvertiserID INT,
Depth SMALLINT,
Position SMALLINT,
QueryID INT,
KeywordID INT,
TitleID INT,
DescriptionID INT,
UserID INT
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE LOCATION '/kddcup2012/track2/testing';
Create external table user (
UserID INT,
Gender TINYINT,
Age TINYINT
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE LOCATION '/kddcup2012/track2/user';
Create external table query (
QueryID INT,
Tokens STRING
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE LOCATION '/kddcup2012/track2/query';
Create external table keyword (
KeywordID INT,
Tokens STRING
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE LOCATION '/kddcup2012/track2/keyword';
Create external table title (
TitleID INT,
Tokens STRING
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE LOCATION '/kddcup2012/track2/title';
Create external table description (
DescriptionID INT,
Tokens STRING
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE LOCATION '/kddcup2012/track2/description';
Create external table solution (
RowID BIGINT,
Clicks INT,
Impressions INT,
Private BOOLEAN
) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE LOCATION '/kddcup2012/track2/solution';
gawk '{print NR"\t"$0;}' training.txt | \
hadoop fs -put - /kddcup2012/track2/training/training.tsv
gawk '{print NR"\t"$0;}' test.txt | \
hadoop fs -put - /kddcup2012/track2/testing/test.tsv
hadoop fs -put userid_profile.txt /kddcup2012/track2/user/user.tsv
tail -n +2 KDD_Track2_solution.csv | sed -e 's/Public/FALSE/g' | sed -e 's/Private/TRUE/g' | gawk '{print NR","$0;}' \
hadoop fs -put - /kddcup2012/track2/solution/solution.csv
hadoop fs -put queryid_tokensid.txt /kddcup2012/track2/query/tokensid.tsv
hadoop fs -put purchasedkeywordid_tokensid.txt /kddcup2012/track2/keyword/tokensid.tsv
hadoop fs -put titleid_tokensid.txt /kddcup2012/track2/title/tokensid.tsv
hadoop fs -put descriptionid_tokensid.txt /kddcup2012/track2/description/tokensid.tsv
Converting feature representation by feature hashing
http://en.wikipedia.org/wiki/Feature_hashing
mhash is the MurmurHash3 function to convert a feature vector into a hash value.
create or replace view training2 as
select
rowid,
clicks,
(impression - clicks) as noclick,
mhash(concat("1:", displayurl)) as displayurl,
mhash(concat("2:", adid)) as adid,
mhash(concat("3:", advertiserid)) as advertiserid,
mhash(concat("4:", depth)) as depth,
mhash(concat("5:", position)) as position,
mhash(concat("6:", queryid)) as queryid,
mhash(concat("7:", keywordid)) as keywordid,
mhash(concat("8:", titleid)) as titleid,
mhash(concat("9:", descriptionid)) as descriptionid,
mhash(concat("10:", userid)) as userid,
mhash(concat("11:", COALESCE(gender,"0"))) as gender,
mhash(concat("12:", COALESCE(age,"-1"))) as age,
-1 as bias
from (
select
t.*,
u.gender,
u.age
from
training t
LEFT OUTER JOIN user u
on t.userid = u.userid
) t;
create or replace view testing2 as
select
rowid,
array(displayurl, adid, advertiserid, depth, position, queryid, keywordid, titleid, descriptionid, userid, gender, age, bias)
as features
from (
select
rowid,
mhash(concat("1:", displayurl)) as displayurl,
mhash(concat("2:", adid)) as adid,
mhash(concat("3:", advertiserid)) as advertiserid,
mhash(concat("4:", depth)) as depth,
mhash(concat("5:", position)) as position,
mhash(concat("6:", queryid)) as queryid,
mhash(concat("7:", keywordid)) as keywordid,
mhash(concat("8:", titleid)) as titleid,
mhash(concat("9:", descriptionid)) as descriptionid,
mhash(concat("10:", userid)) as userid,
mhash(concat("11:", COALESCE(gender,"0"))) as gender,
mhash(concat("12:", COALESCE(age,"-1"))) as age,
-1 as bias
from (
select
t.*,
u.gender,
u.age
from
testing t
LEFT OUTER JOIN user u
on t.userid = u.userid
) t1
) t2;
Compressing large training tables
create table training_orcfile (
rowid bigint,
features array<int>,
label int
) STORED AS orc tblproperties ("orc.compress"="SNAPPY");
Caution: Joining between training table and user table takes a long time. Consider not to use gender and age and avoid joins if your Hadoop cluster is small.
-- SET mapred.reduce.tasks=64;
-- SET hive.auto.convert.join=false;
INSERT OVERWRITE TABLE training_orcfile
select
binarize_label(clicks, noclick, rowid, features)
as (rowid, features, label)
from
training2
CLUSTER BY rand(); -- shuffle
-- SET mapred.reduce.tasks=-1;
-- SET hive.auto.convert.join=true;
create table testing_exploded as
select
rowid,
feature
from
testing2
LATERAL VIEW explode(features) t AS feature;